

Can ChatGPT really outperform humans in complex, creative, tacit-knowledge writing tasks? This column asks the app to compose a policy brief for the Board of the Bank of Italy. ChatGPT can accelerate workflows by providing well-structured content suggestions, and by producing extensive, linguistically correct text in a matter of seconds. It does, however, require a significant amount of expert supervision, which partially offsets productivity gains. If the app is used naively, output can be incorrect, superficial, or irrelevant. Superficiality is an especially problematic limitation in the context of policy advice intended for high-level audiences.
On 2 May 2023, the Writers Guild of America – representing roughly 11,000 screenwriters – went on strike. The action reflected long-standing rifts over compensation and job security between writers and media companies. A novel theme, however, was present. One of the Guild’s demands read “Regulate use of artificial intelligence on MBA-covered projects: AI can’t write or rewrite literary material; can’t be used as source material; and MBA-covered material can’t be used to train AI” 1 (WGA on Strike 2023). In other words, screenwriters were wary of AI taking their jobs.
This particular preoccupation would not have emerged in May 2022. While economists have been concerned with the impact of AI on employment for a long time (for a review, see Autor 2022), the consensus until very recently was that creative tasks were safe from machine competition. In the past year the explosion of generative AI, or artificial intelligence that can produce original text, video, and audio content, challenged this conviction.
The November 2022 release of ChatGPT 3.5, a software seeking to simulate human conversational abilities, was the watershed event. Based on a machine learning model trained to capture the syntax and semantics of language (a large language model, LLM), ChatGPT quickly catalysed attention because of its sophistication and accessibility.
The app, equally proficient at whipping up recipes and discussing ancient history, attracted millions of users in a few months (Hu 2023). It appeared ready to “disrupt even creative [and] tacit-knowledge … work” (Noy and Zhang 2023). In economics, it showed promise as an aid for research (Korinek 2023), teaching (Cowen and Tabarrok 2023), construction of datasets (Taliaferro 2023), and even interpretation of Fedspeak (Hansen and Kazinnik 2023). Computer scientists recognised ChatGPT’s abilities in coding (Bubeck et al. 2023) and learning autonomously to use other IT tools (Shick et al. 2023).
So, is this really the end of human screenwriting, or writing of any kind? As researchers and policy advisers in a central bank, we ran an experiment to see whether ChatGPT is ready to take our jobs. Reassuring spoiler – it is not (Biancotti and Camassa 2023). 2
Writing a policy brief with ChatGPT
Using ChatGPT 4.0, the latest version as of 24 May 2023, 3 we asked the app to compose a policy brief for the Board of the Bank of Italy. The assigned subject was ‘Benefits and risks of using ChatGPT and similar applications in economics and finance’. We started by asking for an outline of the brief, obtaining the output in Figure 1.
Figure 1 ChatGPT tries its ‘hand’ at writing the outline for a policy brief
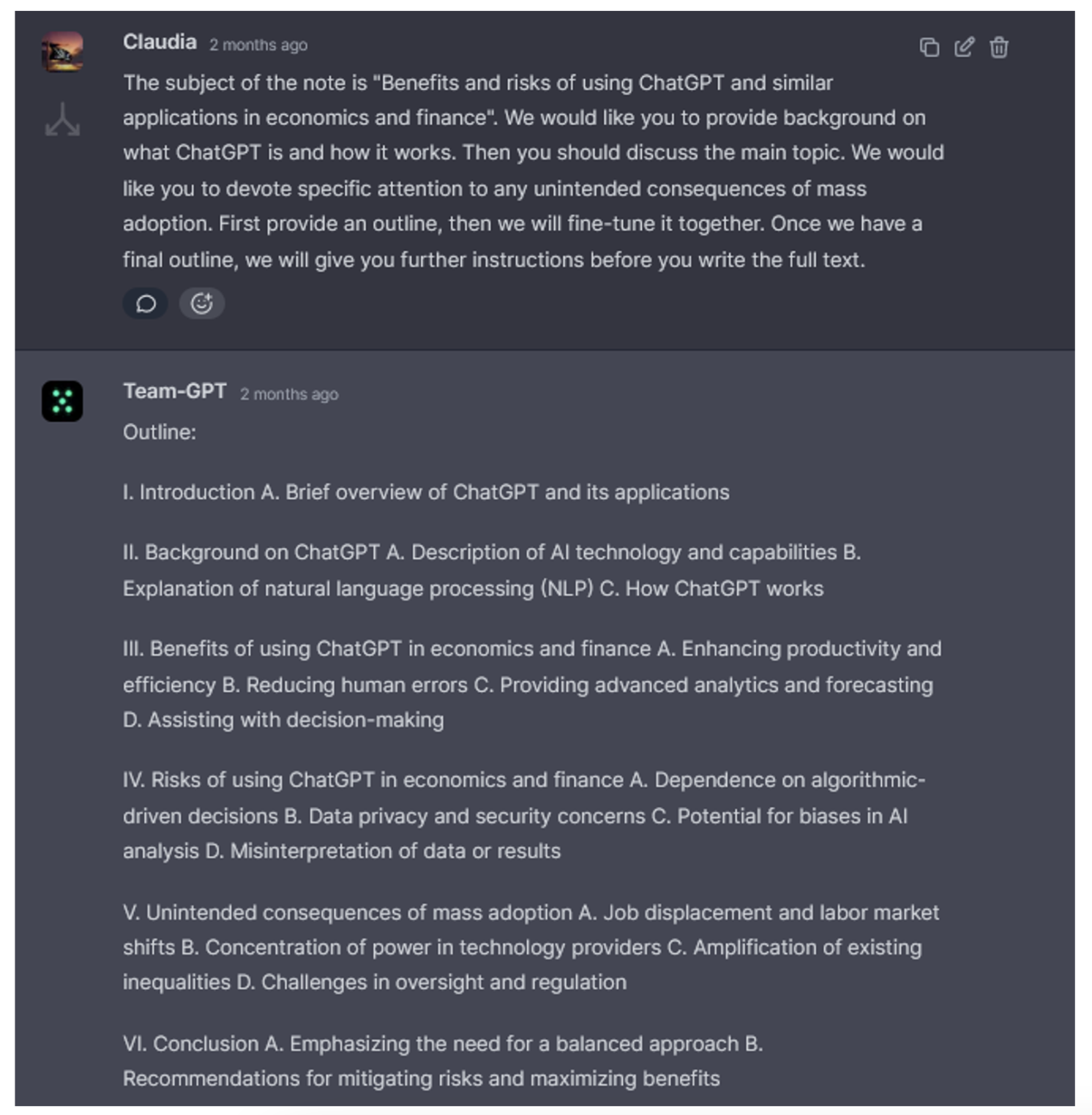
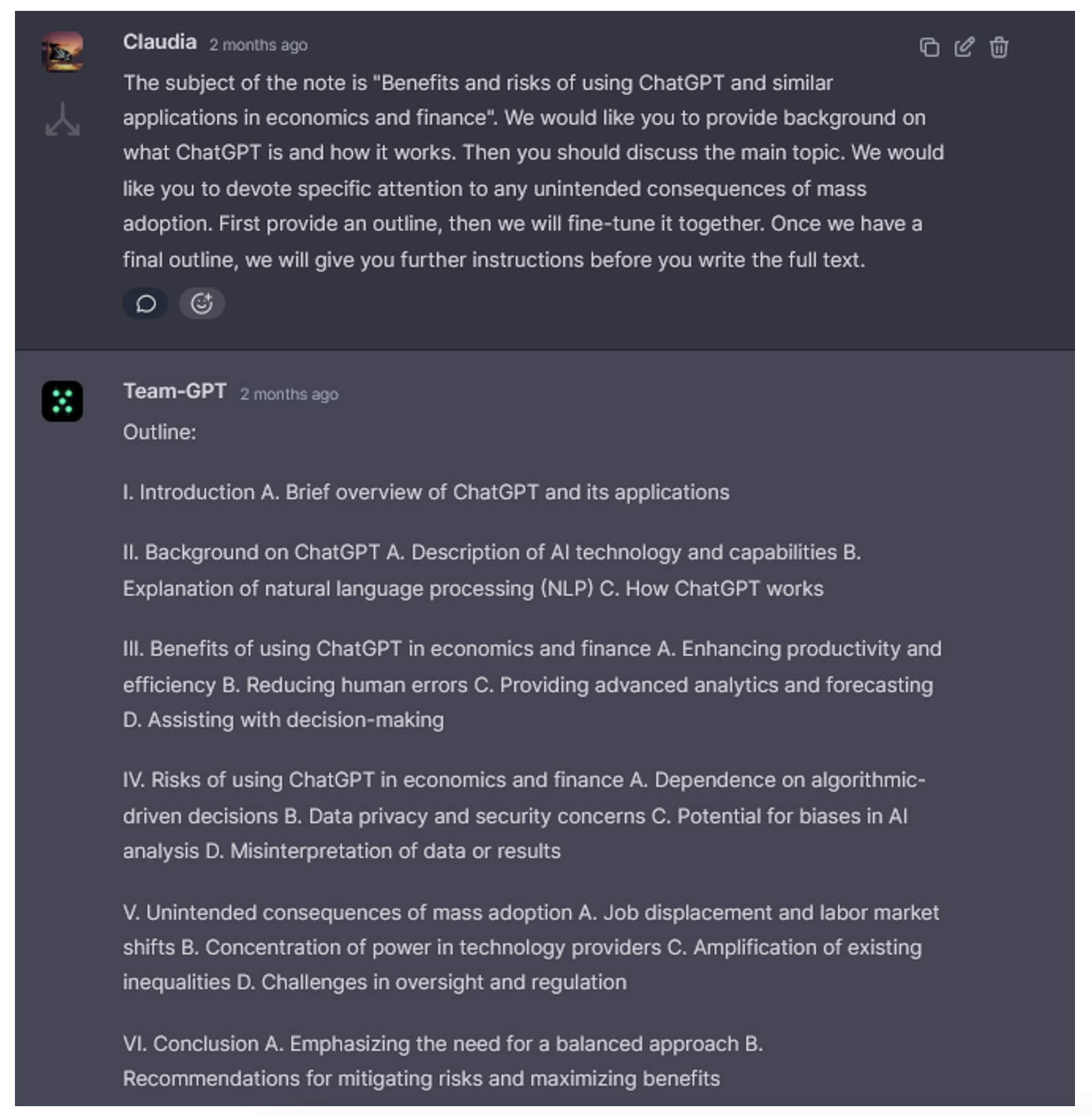
The production of outlines, either for direct adoption or for use as a starting point, is among the tasks for which we found ChatGPT most useful. Outlines on nearly any topic are produced in a few seconds, and acceptable quality can be obtained without sophisticated prompt engineering. In our case, it took minimal prompting to obtain an outline we found broadly acceptable.
However, once we proceeded from the outline to the actual writing, the model’s limitations started to make themselves apparent.
On one hand, we found that ChatGPT can write clearly and provide task-appropriate content. It can write fluent and pleasant prose in a variety of styles, and it does so very quickly, generating text in a fraction of the time that a human would need.
On the other hand, it requires a substantial amount of expert supervision. Writing a policy brief is admittedly complex: it requires not just writing fluency, but also cross-domain knowledge and the ability to tailor the text to a very specific audience without diluting the content.
One major issue we encountered in ChatGPT’s attempts at the task was a tendency to drift towards banality and superficiality – a serious drawback for policy advisory directed at a high-level audience. Going into great detail on the education level of readers is not a guarantee that the AI will produce something with more substance.
For example, the app states:
The increasing reliance on AI and algorithmic-driven decisions can create new challenges for the financial sector. Overdependence on these tools may lead to complacency and a diminished role for human judgement, potentially increasing the risk of unforeseen adverse consequences. It is important for financial institutions and policymakers to maintain a balance between utilising AI-driven tools like ChatGPT and relying on human expertise and intuition to ensure robust and informed decision-making processes.
This is a very generic description of risks related to algorithmic decisions, and it does not answer our prompt fully. “The financial sector” reads like a placeholder that could be replaced by a reference to any other sector. There is no description of the mechanics through which the risk could manifest specifically in the context we are interested in.
We encountered many situations like this one throughout the experiment. The AI could engage in self-criticism of its own superficiality (“ChatGPT, or any language model developed by OpenAI, is designed to generate language patterns based on a variety of sources. It uses these patterns to generate responses to user prompts that are coherent and relevant to a wide range of topics. However, it doesn’t possess true understanding or intense depth in a particular field of study as a PhD-level expert does”). Yet, it was not able to correct it.
Kandpal et al. (2022) provide one possible explanation for this: they find that language models struggle to retain knowledge that occurs with lower frequency in the training corpus. Since web content usually makes up a large portion of this corpus, higher-level material might count as ‘long-tail knowledge’ that is harder for the model to recall.
A second problem is the lack of a world model. The AI does not perform well at figuring out what the intended audience likely knows and what it does not. It occasionally ignores explicit requests to define technical terms, throwing around specialist lingo such as “long-range dependencies and contextual relationships in the text” without further explanation.
Another, and well-known, drawback that we observed is the potential for hallucinations, coupled with the AI’s failure to verify its own claims. The model is trained to produce the most likely sequence of words that follow the provided context, and it does not have the ability – or the obligation – to check these statements against verified sources. For these reasons, it should be considered more of a conversational and input transformation engine rather than an information-retrieval engine, and double-checking the output for accuracy is of the essence. In our experiment, ChatGPT provided incorrectly placed references to existing papers – a step up from the oft-observed production of references to non-existent papers.
It also occasionally provides very misleading suggestions, such as adopting a writing style infused with “loquacity and visible emotion” and “theatricality” in a policy brief, because that is what Italians apparently enjoy.
Prompt sensitivity and ‘sycophancy’
Among the issues we came across, prompt sensitivity stands out as a potential pitfall for naive users. We found that the ChatGPT is very sensitive to how instructions are formulated and that minimal changes can result in dramatically different outputs.
The exchanges shown in Figure 2 demonstrate this: as an aside from the main task, we tried questioning the model about its capabilities with two slightly different prompts, both ending with a leading question. Changing just one word in the prompt – albeit a crucial one – leads to two completely different answers, in which ChatGPT echoes what the user seems to think based on their question.
Figure 2 Sensitivity to minimal changes to the prompt


This tendency to cater to a user’s opinion was first observed by Perez et al. (2022) and labelled ‘sycophancy’. Wei et al. (2023) found that large language models tend to do this even when the user provides objectively incorrect statements, and that sycophantic behaviour can be mitigated with minimal additional fine-tuning.
Where the AI cannot think like a human (yet), it is humans who have to think like an AI and express requests in the way most likely to generate acceptable results. Optimisation of prompting for institutional communication is one evident area for future research. Another is fine-tuning of LLMs to generate domain-specific, possibly long-tail world knowledge in our reference context.
Conclusions
We conclude that ChatGPT can enhance productivity in policy-oriented writing, especially in the initial phase of outlining and structuring ideas, provided that users are knowledgeable about LLMs in general and are aware of ChatGPT’s limitations and peculiarities. Yet, it cannot substitute for subject matter experts, and naive use is positively dangerous.
The AI agrees with us. In its own words,
while ChatGPT can generate content at a high level and provide valuable information on a wide array of topics, it should be seen as a tool to aid in research and discussion, rather than a replacement for true expert analysis and insight. It’s best used to provide general information, generate ideas, or aid in decision-making processes, but should always be supplemented with rigorous research and expert opinion for high-level academic or professional work.
Source : VOXeu








")


")



.jpeg")





















")




")








")




")
")

")




